
What is Conversational AI? And the challenge
Date : 2021-10-14 View : 1084
It is reported by Markets and Markets, a consultancy, that the global conversational AI market size is expected to grow from USD 4.8 billion in 2020 to USD 13.9 billion by 2025, at a Compound Annual Growth Rate (CAGR) of 21.9% during the forecast period.
Conversational artificial intelligence (AI) refers to applications, like chatbots or virtual agents, which users can talk to and receive a responses from in in a way that mimics human conversation. The best Conversational AI offers an end result that is indistinguishable from could have been delivered by a human.
How does conversational AI work?
Responding to a question involves several steps: converting a user’s speech to text, understanding the text’s meaning, searching for the best response to provide in context, and providing that response with a text-to-speech tool.
The typical gap between responses in natural conversation is about 300 milliseconds. For an AI application to imitate human interaction, it might have to run a dozen or more neural networks in sequence as part of a multilayered task — all within that 300 milliseconds or less.
If it takes longer for each model to run, the response is too sluggish and the conversation becomes jarring and unnatural.
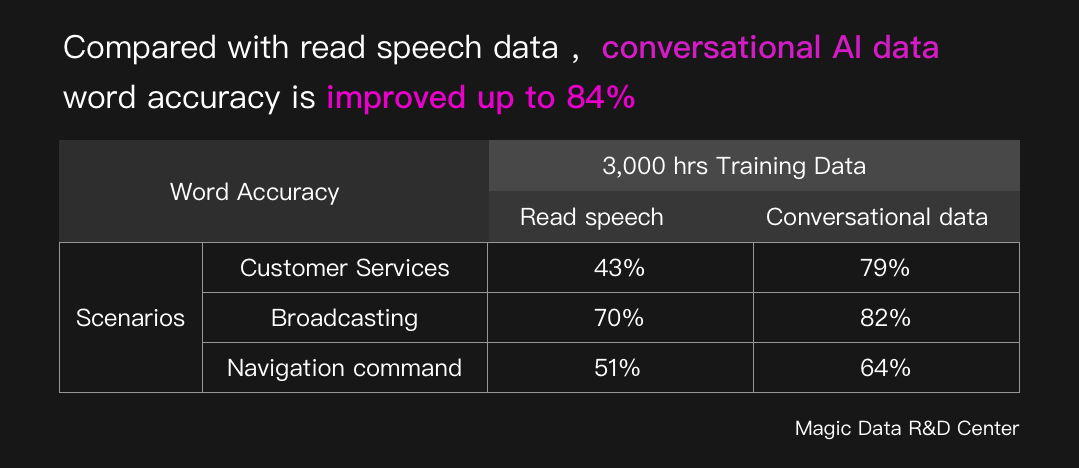
What challenge is conversational AI facing?
Chatbots and virtual assistants are the two most common application of conversational AI, both at their early period though. For example, in most cases, we have to talk to the virtual assistant: “open the air conditioner,” when we are feeling the indoor temperature is too high, rather than saying “It’s a hot day!” It reflects that the built-in AI model can not understand the meaning of our natural sayings yet and can not make the correct response in that way.
“The essence of conversation AI is human being able to express naturally”, says Magic Data Tech’s CEO, Dr. Qingqing ZHANG. Although the end result may be delivered in various ways, the first things a conversational AI need to deal with is to recognize the speech. In terms of speech recognition, as far as Dr. ZHANG’s concerned, there are two main challenges for conversational AI.
The first one is the different way of expression between individuals. Due to culture, location, and education background differences, every one of us has our unique way of expression. This leads to misunderstanding in human to human communication, let alone human-computer interaction. For an AI based interaction application, English is not a single language, but a language used by the billions of people.
The second challenge is the inverted word order, hesitant and irresolute speech phenomenon in natural human communication. In addition, in conversation of multiple speakers, there are interruption and overlap speaking, which also bring difficulties for building conversational AI.
In these circumstances, authentic conversational training data are the key point for conversational AI.
Magic Data Tech AI training data solutions
Compared to traditional scripted speech data, conversational data has the following features: natural speech style, close to real life and business scenes, covering complex speech phenomenon, themed spontaneous speech. Conversational data has many advantageous for building a conversational AI model. However, this does not mean that scripted data is outdated. Traditional scripted data has advantageous in high content relevance and high phoneme coverage. More importantly, it is more easy to obtain with lower unit-price in most cases.
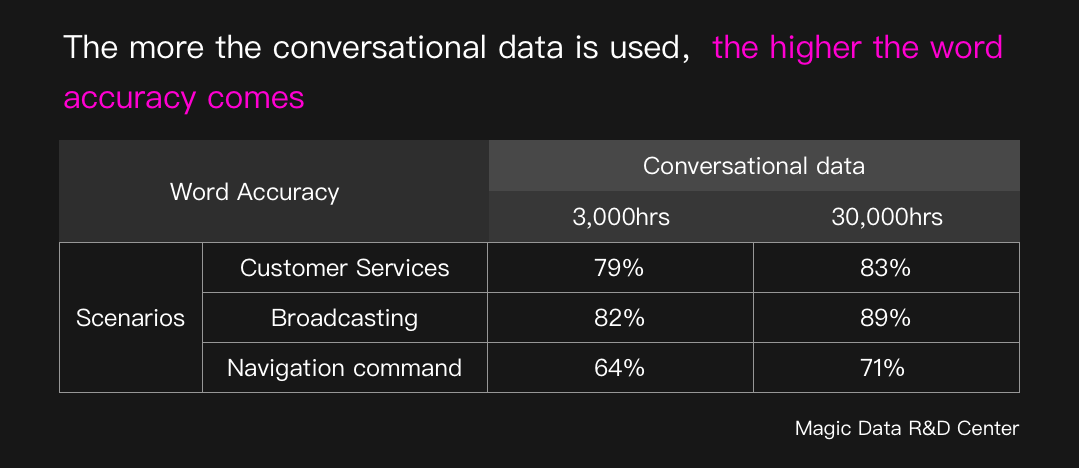
Thus, it is recommended to combine conversational data and scripted data in developing conversational AI. At the beginning and universal level of building ASR model, more scripted data can be deployed to build up baseline; for advanced level ASR model, more spontaneous conversational data should be used for better performance.
As an advanced global AI training data services provider, Magic Data Tech has always been dedicating in assisting our partners in achieving their goal. With its powerful technical strength and outstanding management, we have secured one-stop AI training data solution ability and built the world’s largest conversational training dataset: over 140,000 hours of speech corpus covering more than dozens of languages, serving over 100 clients in field of financial services, automobile sector, smart home, smart wearables, and SNS.
It has been 5 years since Magic Data Tech was founded in 2016. We are grateful for the recognition the industry has given to us and proud of our tested performance. The past 5 years has been a very productive time for us. We are celebrating our 5th anniversary and there is a special offer: buy 600 hours of training dataset and get 180 hours of conversational Chinese ASR training dataset and 20 hours of Chinese TTS training dataset for FREE.
Contact our data experts business@magicdatatech.com for data insight and the best data solution for your AI model training.