Industry Solutions
Financial Services

Financial Services
Streamling your business process with enterprise-level security guaranteed.
Our top priority lays on compliance and security.
Revitalizing financial industry by providing one-stop AI data solutions for customer service, virtual counter, virtual assistant, targeting marketing, and other AI applications.
Scenarios

Customer Service
Dial In/Out, Collect Accounts Receivable

Smart Meeting
Realtime Captioning,Translation,Meeting Minutes Generation

Automated Invoice Processing
Identity Certification, Warranty OCR, Medical Record OCR

Virtual Human
Smart Shopping Guidance, Marketing
Challenge
Imprecise voice recognition of customer service scenario
Unable to correctly understand commands and queries
Impersonal and unnatural communication
Different format between invoices, warranties, and medical records
Annotator® AI-Assisted Annotation Platform
Audio Annotation
Text Annotation
Image Annotation
- Customer Service - Customer service annotation
- Virtual Human - Command and query annotation
- Smart Meeting - Meeting scenarios voice annotation
- Virtual Human - Rhythm, Text segmentation, part-of-speech, and phoneme annotation
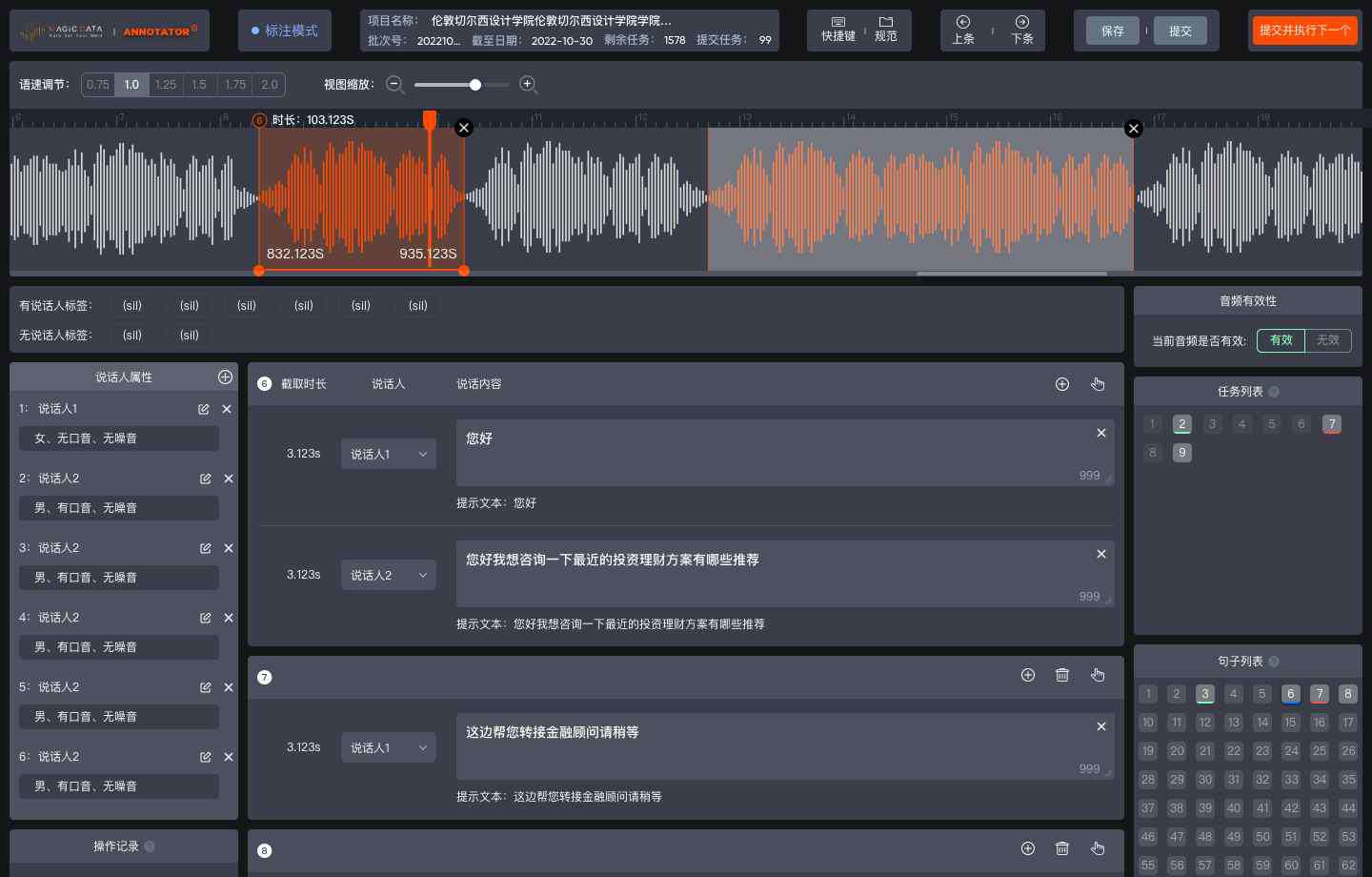
- Customer Service - User queries relevance annotation
- Virtual Human - User interaction content annotation
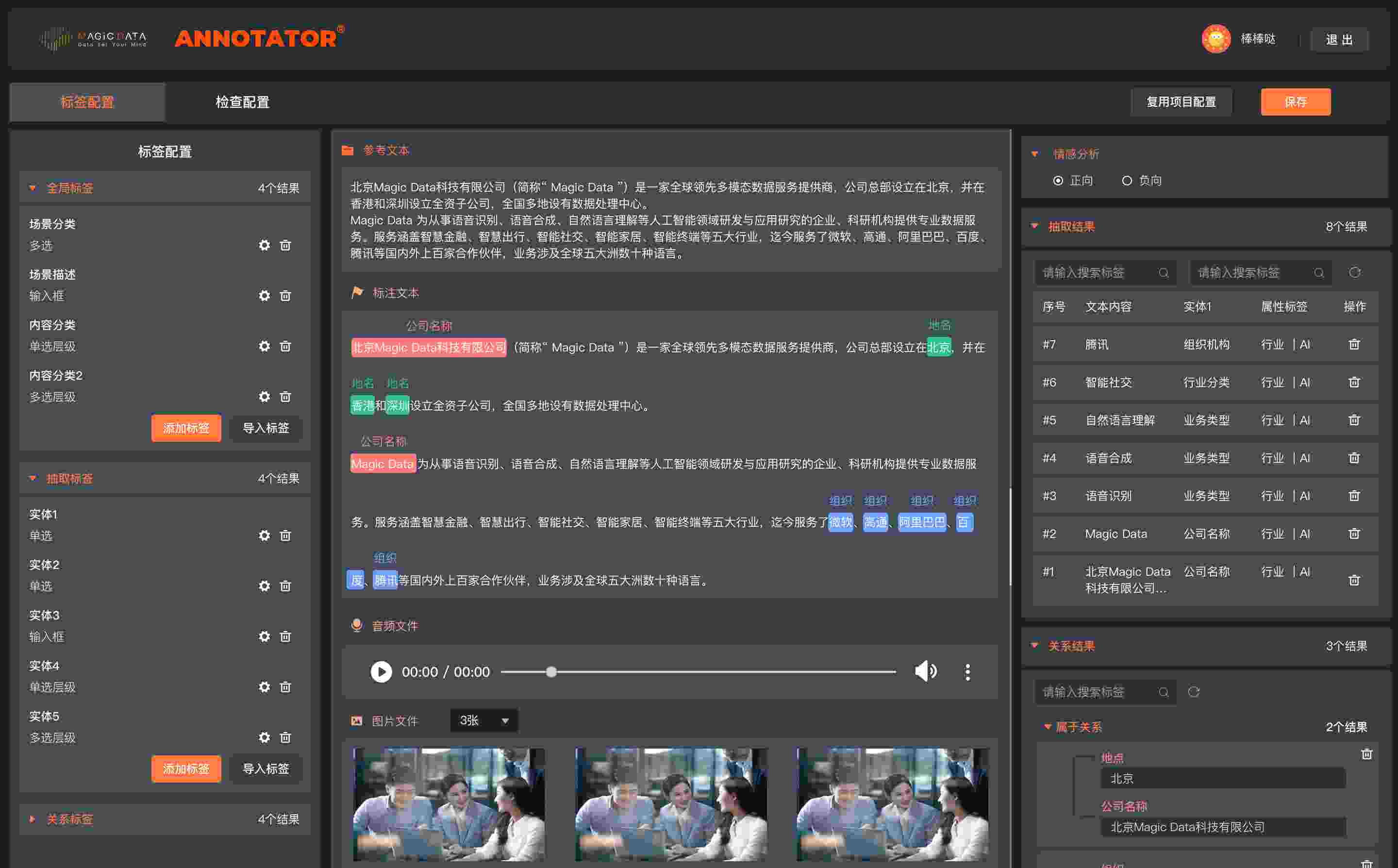
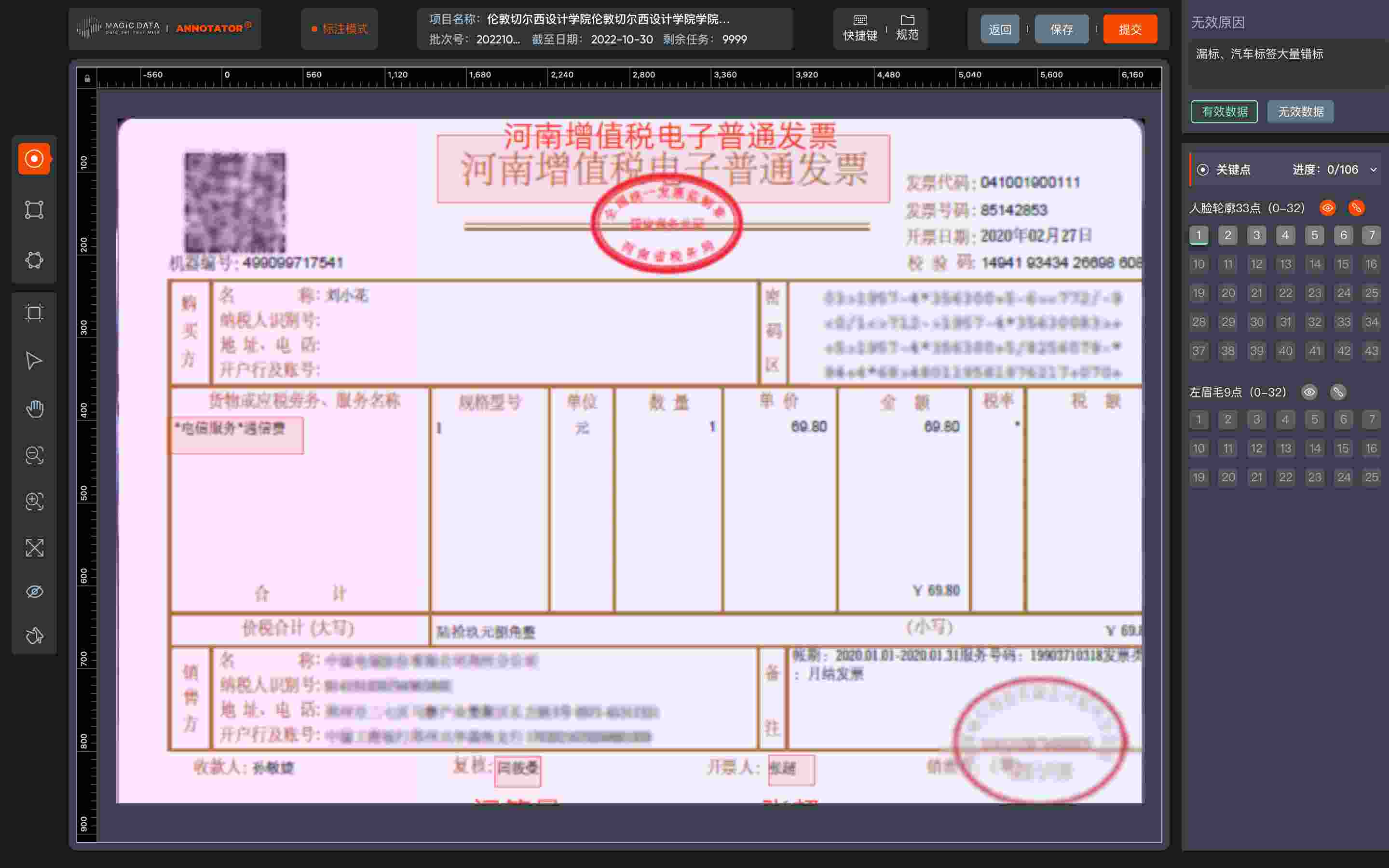
- Automated Invoice Processing - Invoice OCR annotation
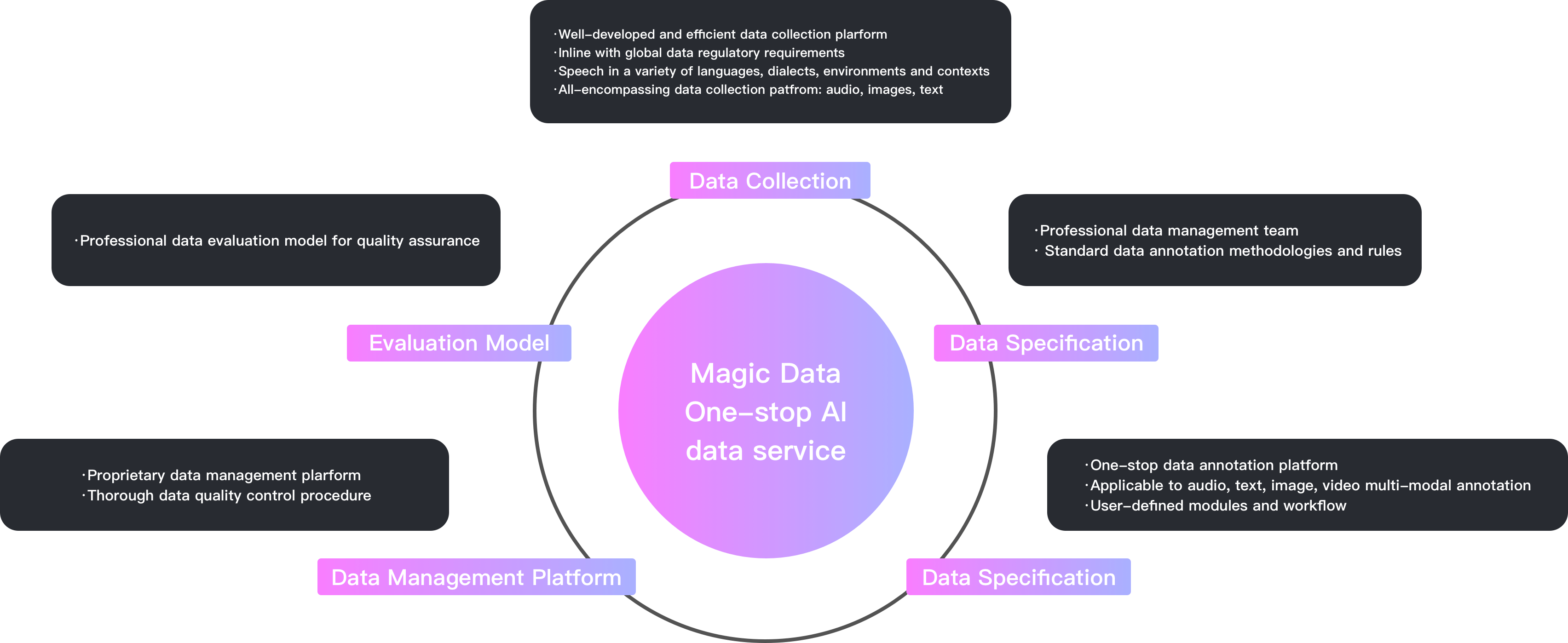
MD Dataset Portfolio
Speech Recognition
→
Text-to-Speech
→
Natural Language Understanding
→
OCR
→
Contact us for data collection and annotation service









Related Datasets
MDT-LG004 German Lexicon
MDT-NB007 English In-Vehicle Command and Query Text Corpus
[Open-Source]
MDT-AF074 Mandarin Chinese Conversational Speech Corpus
Play Audio
MDT-NF005 Chinese English Filipino Parallel Corpus
MDT-RJ003 Korean Spoken Speech Dataset
This dataset is designed to train AI models that better understand spoken Korean, improving natural interaction in speech recognition. It features diverse real-life dialogues with high transcription accuracy. Key phonological changes like liaison and batchim assimilation are carefully annotated. Complete sentences and emotion-aware punctuation help models capture Korean speech patterns and sentence-ending intent.