Industry Solutions
Smart Home

Smart Home
Optimizing AI models with Magic Data AI data total solution.
Make your state-of-the-art products more intelligent and competitive.
Scenarios

Household Appliance Automation
Household appliance wake-up,remote control,consumer robots,Smart household appliance

Smart Device Control
Smart phone/tablet,wearable,remote control

Home Security
Security monitoring of the elderly and children, maintenance of household appliance, monitoring of break-in, motion sensor

Virtual Assistant
Information query, travel arrangement, phone call, entertainment
Challenge
Imprecise voice recognition in residence and usage scenario
Unable to correctly understand ambiguous and long-tail queries
Stiff and unnatural response
Limited data on safety monitoring
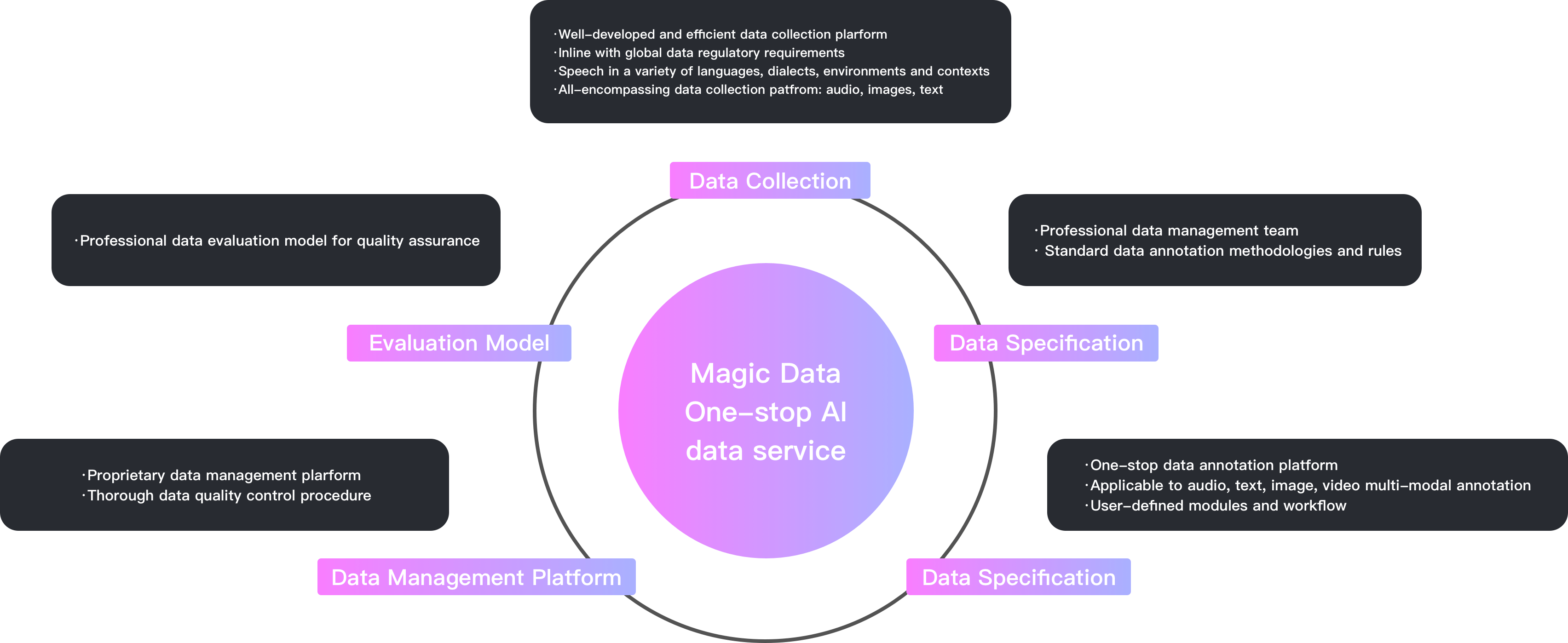
Annotator® AI-Assisted Annotation Platform
Audio Annotation
Text Annotation
Image Annotation
- Household Appliance Automation - Speech command and query annotation (ASR)
- End-User Device Control - Speech command and query annotation (ASR)
- Virtual Assistant - Speech command and query integration annotation (ASR)
- Virtual Assistant - Rhythm, text segmentation, part-of-speech, and phoneme annotation (TTS)
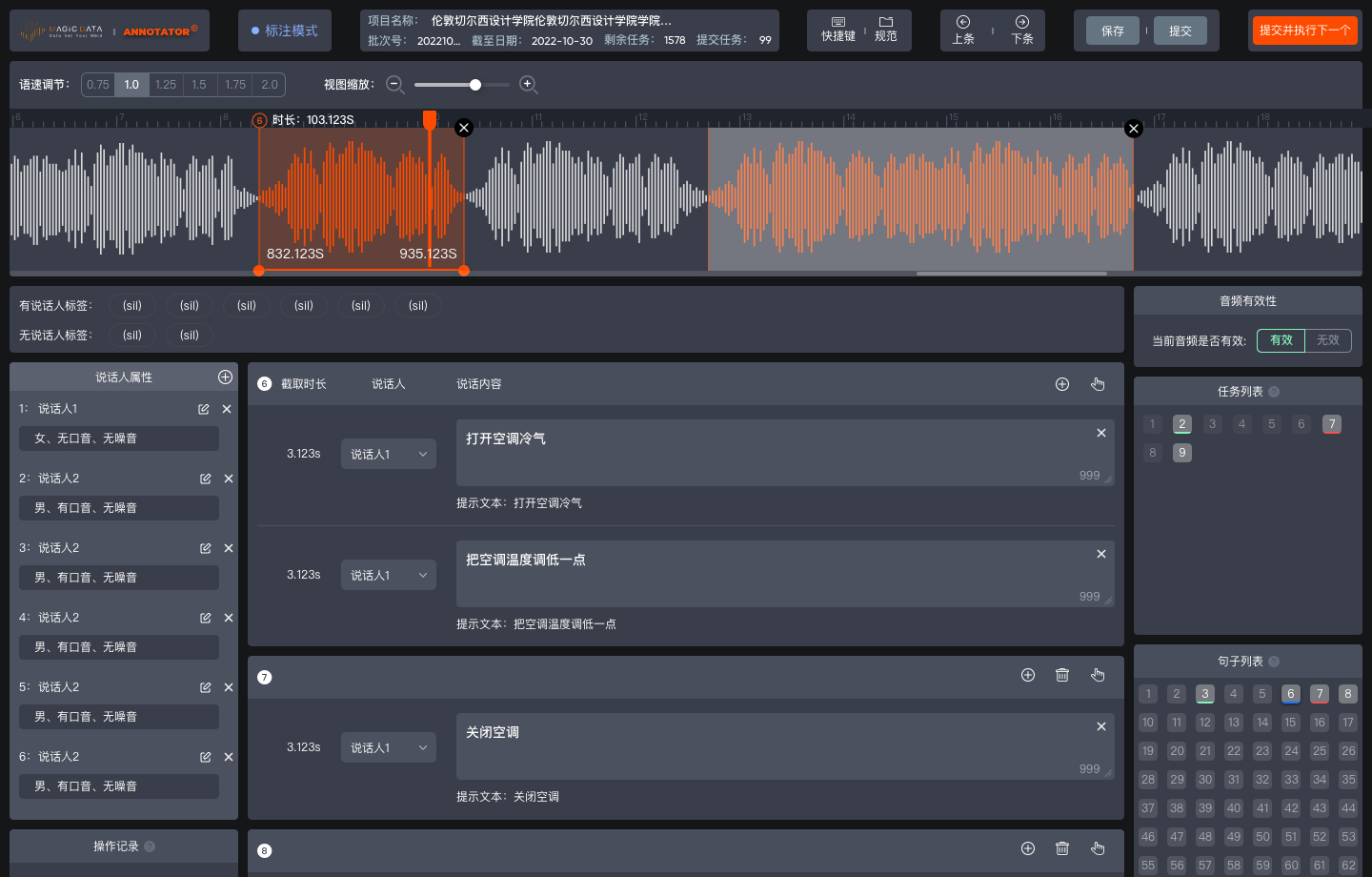
- Household Appliance Automation - Command generalization (NLP)
- End-User Device Control - Command generalization (NLP)
- Virtual Assistant - Interaction query generalization (NLP)
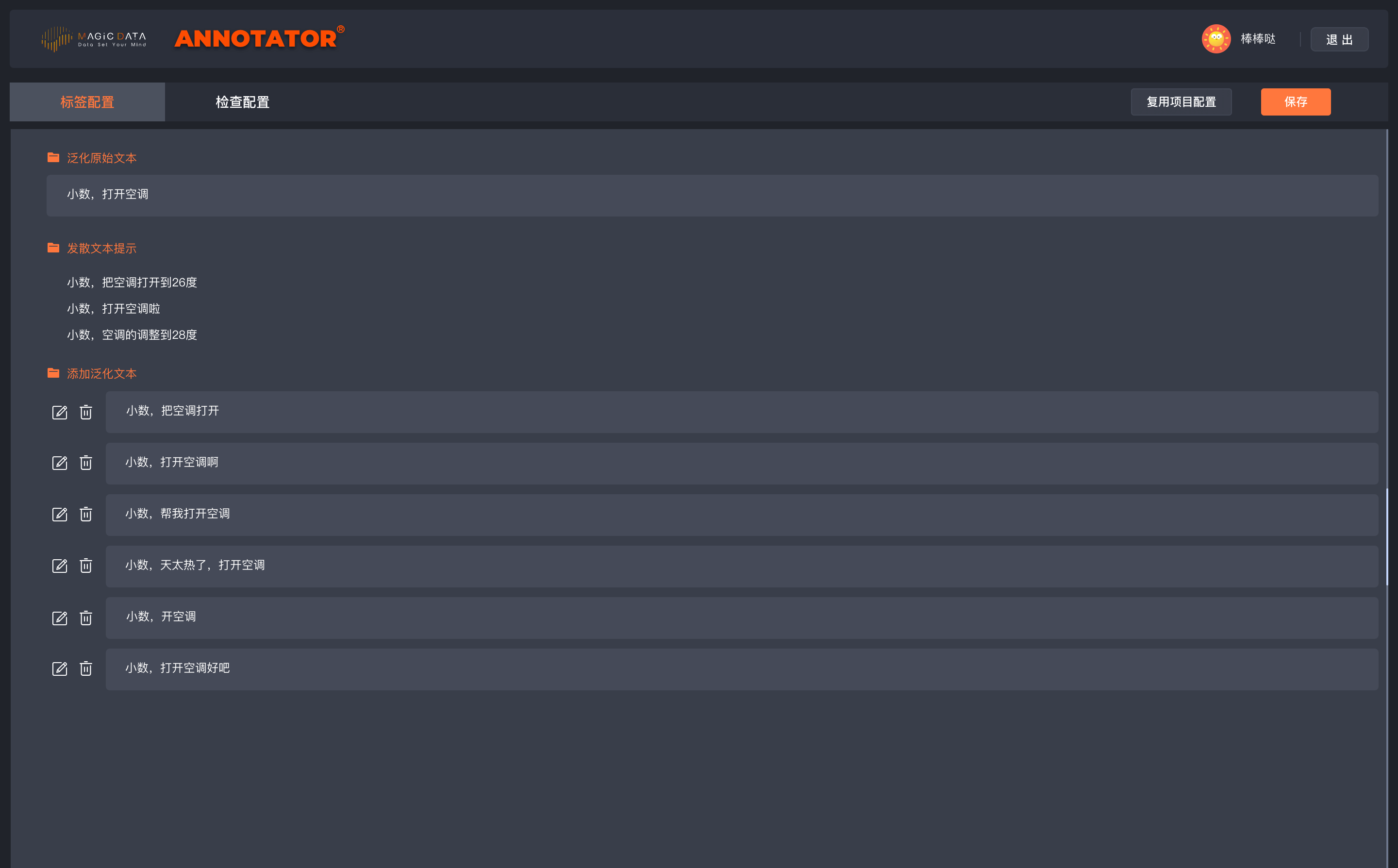
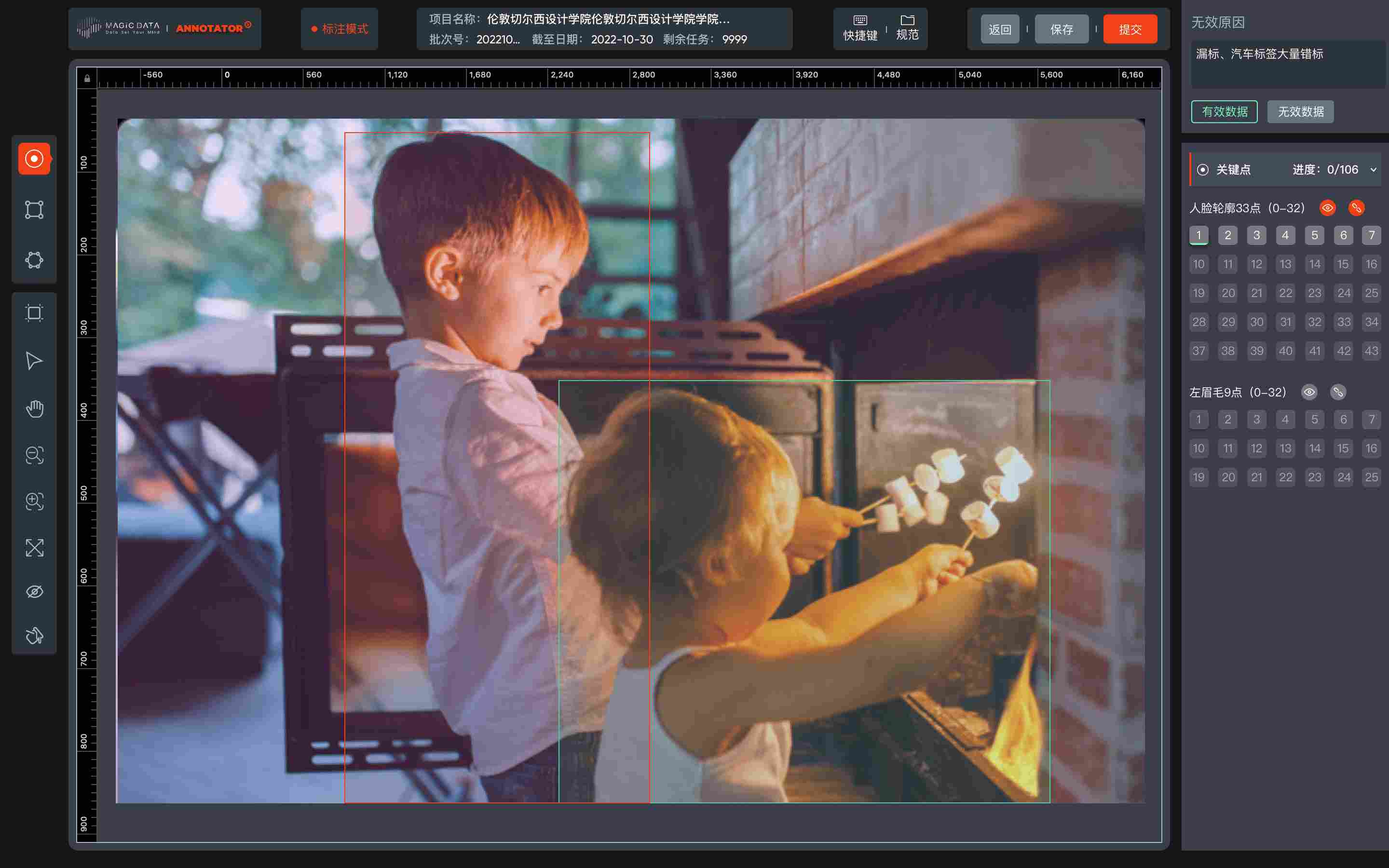
- Home Security - Interior and exterior home image annotation (CV)
MD Dataset Portfolio
Speech Recognition
→
Text-to-Speech
→
Natural Language Understanding
→
OCR
→
Contact us for data collection and annotation service







Related Datasets
MDT-RI003 English Spoken Speech Dataset
This dataset is designed to train AI models that better understand spoken English, improving natural interaction in speech recognition. It captures features like connected speech, weak forms, and fillers from real-life conversations. With diverse speakers and high transcription accuracy, it helps models learn English prosody and rhythm for more accurate recognition.
MDT-AF078 Spanish Conversational Speech Corpus
Play Audio
MDT-NF021 Chinese Educational Customer Service Text Corpus
MDT-AF058 Mandarin Chinese Scripted Speech Corpus—Keyword Spotting
Play Audio
MDT-RJ003 Korean Spoken Speech Dataset
This dataset is designed to train AI models that better understand spoken Korean, improving natural interaction in speech recognition. It features diverse real-life dialogues with high transcription accuracy. Key phonological changes like liaison and batchim assimilation are carefully annotated. Complete sentences and emotion-aware punctuation help models capture Korean speech patterns and sentence-ending intent.
Multi-Emotional Natural Speech Dataset
Magic Data has newly introduced the "Multi-Emotional Natural Speech Dataset", comprising various datasets designed to enhance expressiveness and naturalness in speech technology, enabling intelligent devices to exhibit a wide range of emotional expressions. This dataset significantly enhances the emotional expressiveness of large speech models. By leveraging our dataset, the expressiveness and emotional authenticity of large speech models can be greatly improved.
Play Audio