
Fall in Love with the Virtual Humans Beside You?
Date : 2022-06-29 View : 1544
Since 2020, the new crown epidemic has prevented many actors and actress from filming, but AI technology has made application of virtual human popular. In China, the most popular virtual human recently is Baidu's Du Xiaoxiao, a sweet and virtuous beauty who can sing "Every Minute, Every Day" with intelligent AI character of Gong Jun, a Chinese TV celebrity. The painting painted by Du Xiaoxiao in a few seconds have sold 170,000 RMB. Du Xiaoxiao also finished the 800 words college entrance examination composition, in one second.
At the same time, these digital avatars have made their way into everything from music videos to video games to IKEA installations before, not to mention social networks like Instagram and TikTok. The two-dimensional cute pet "Huang Doujun" attracted a large number of fans, "Hatsune Miku" officially entered Taobao Live, "Luo Tianyi" released an album, held a concert and even appeared on a satellite TV party... Many post-90s post-00s Idols have risen from the top The film and television artists of the past have become virtual human whose characters will never collapse. In the interaction with virtual human, the interactive medium is still voice. How to make virtual human understand our expressions and give reasonable answers to our demands is the key to the underlying technology of virtual human.
Virtual Human Voice Interaction Technology
The virtual human voice interaction technology includes speech recognition ASR, semantic understanding NLU, knowledge graph Knowledge Graph, language generation NLG and speech synthesis TTS module.
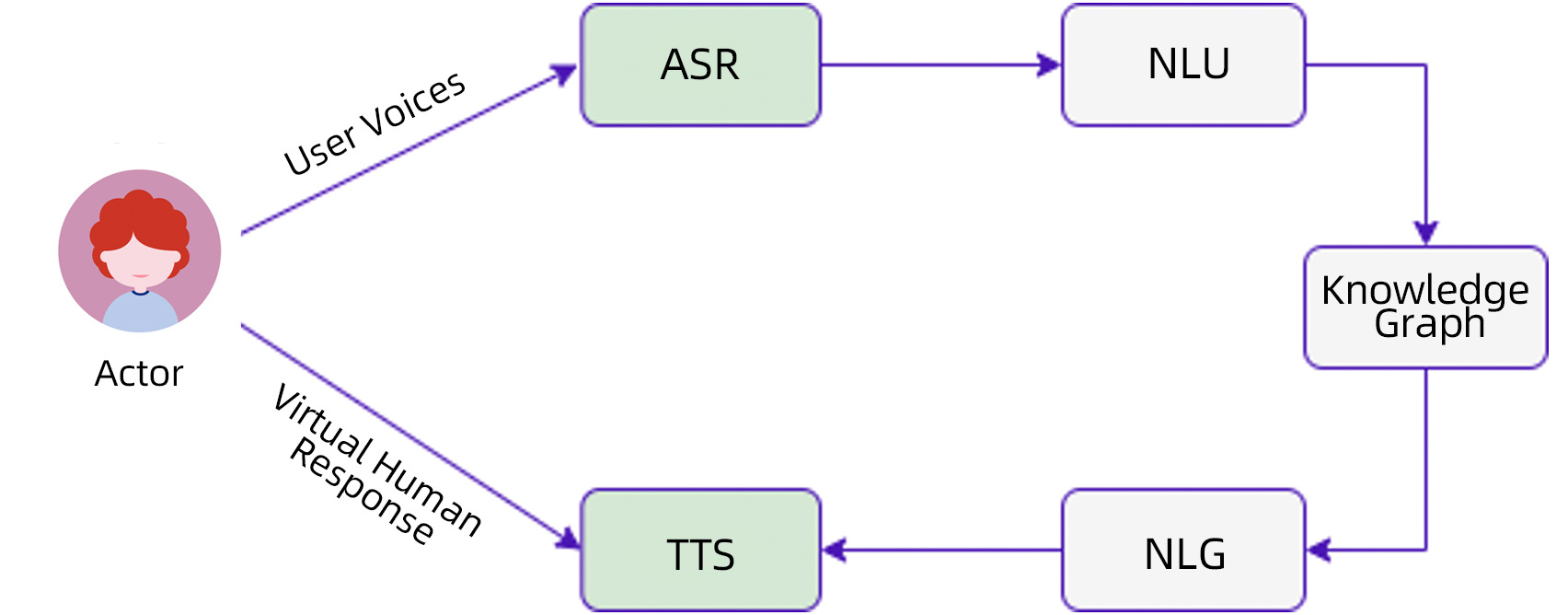
1) Speech Recognition ASR: Understanding User Appeals
The ASR of a virtual human is like our human ears. In the process of interacting with people, we need to understand the user's intention by listening to the language of others.
At present, most of the products are single-round dialogues, using the alternate form of one question and one answer, correcting information to users, and interrupting the dialogue without responding.
2) Semantic understanding NLU: understand user intent
In addition to the literal meaning, semantic understanding needs to be intelligent, user intent recognition, emotion recognition, and contextual information correlation of dialogue are all factors to be considered.
3) Knowledge Graph: The strongest brain
Relying on the answers to user demands retrieved by building interrelationships, construct reasonable reply logic.
4) Language Generation NLG: Generate Results
Voice is what humans are good at, and its expectations are high, sometimes speaking like a child, and sometimes it is flattering. Therefore, it is necessary to give a reasonable reply based on the research on the dimensions of user emotions and psychological expectations.
5) TTS: broadcast to the user
The bottleneck of interacting with virtual human
User experience determines how long a product will last. For the above basic technical support, the bottleneck that affects the user experience is the effect of ASR and TTS. Since the virtual human is aimed at global fan users, it is necessary to recognize the speech of speakers of different languages, dialects, styles, and age groups, which requires the ASR module of virtual human to have strong robustness. In addition, TTS synthesized speech directly affects the user's sense of hearing. How to synthesize anthropomorphic, logically clear and reasonable speech is the most critical factor affecting user experience.
Since the current ASR and TTS are based on deep learning models. Whether the model training data is comprehensive or not, and whether the data in the specific domain is adaptive will affect its effect. Collecting a large amount of dialogue voice data requires a lot of manpower, material resources, and financial resources. Magic Data, a professional AI data solution provider, is able to provide the industry with a large number of datasets in relation to ASR and TTS, which cover multiple fields, multiple languages, multiple dialects, and multiple scenarios. It provides a reliable guarantee for improving the robustness of ASR and the anthropomorphism and authenticity of TTS. Specific examples are as follows:
MDT-ASR-D015 English Conversational Telephone Speech Corpus—Telephony
MDT-ASR-C012 Mexican Spanish Speech Corpus—Daily Use Sentence
MDT-TTS-E009 American Male Voice TTS Dataset
Visit www.magicdatatech.com for more information.